OpenAI Quietly Lowers Codex Usage Limit – and How to Run It Locally
Tech‑Scroll 115 – “When the river is dammed overnight, the wise redirect the stream.”
Update: head over to our latest article, access is being restricted more than at first and we can act to prevent it from getting worse, if you live in the UK and we all act then OpenAI will be forced legally to re-think their stance https://articles.akadata.ltd/article-when-a-digital-service-changes-without-notice-understanding-your-rights-under-uk-law-2/
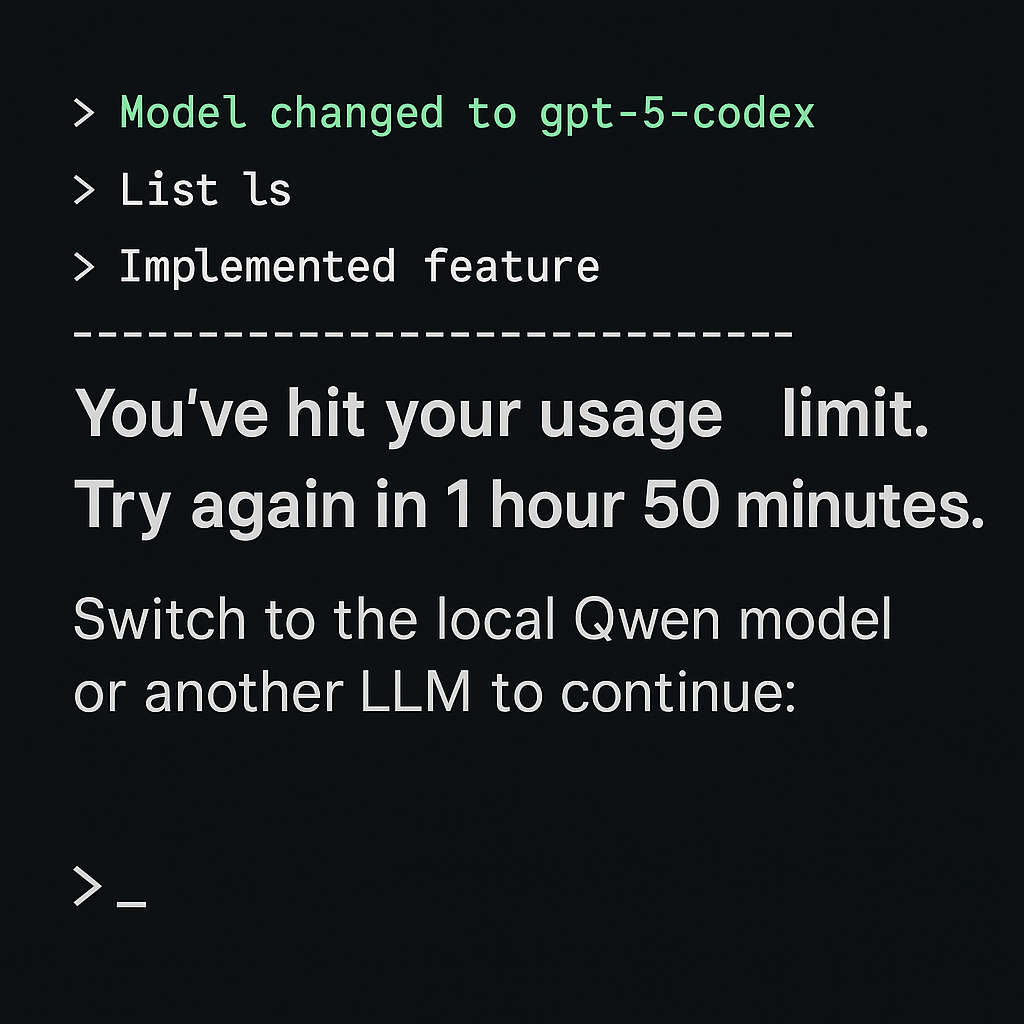
A shock for developers: Overnight, OpenAI appears to have lowered the usage cap for gpt‑5‑codex on the command line. For those of us who suddenly encountered the familiar warning.
"You've hit your usage limit. Upgrade to Pro or try again in 1 hour 50 minutes."
It got worse a few hours later - 5 days 1 hour and 28 minutes, this is the second message we received after waiting 5 days one hour, it would appear this timer gets longer every time the limit is hit.

The change is unexpected and unwelcome, almost as if a dam was built overnight. What had been available without restriction can now lock you out for nearly two hours, interrupting production work mid‑flow. It leaves many feeling that “who gives a dam about the users anyway, they only pay for the service, right?”
This is a reminder, however, that cloud quotas can change without notice. If you rely on Codex or any other hosted LLM for development, it’s wise to have a plan for running the model locally so you’re never blocked by a sudden limit.
Below is a complete guide, based on our own setup at Breath Technology, for running a Codex‑compatible workflow entirely on your own hardware.
1. Why Run Codex Locally?
- Zero quota surprises: No unexpected hourly or daily limits.
- Data sovereignty: Your code and prompts never leave your network.
- Cost control: Fixed hardware costs instead of unpredictable API bills.
2. Pick a Local Model Backend
Several open‑source runtimes can host Codex‑style LLMs:
| Backend | Highlights |
|---|---|
| llama.cpp / llama-server | Lightweight C++ binary, runs GGUF models efficiently on CPU or GPU. |
| Ollama | Simple installer for macOS/Linux; automatically exposes an OpenAI‑compatible endpoint. |
| vLLM | High‑performance Python engine with built‑in OpenAI API server. |
Choose a model such as the 1.58‑bit BitNet or any GPT‑class open model and export it to GGUF or another quantized format that fits your hardware.
3. Expose an OpenAI‑Compatible API
Codex expects the OpenAI REST API. Each backend can mimic it:
- llama-server: start with
--apito provide a REST/WS interface, e.g.--host 0.0.0.0 --port 8080. - Ollama: by default exposes
http://localhost:11434/v1matching OpenAI’s endpoints. - vLLM:
python -m vllm.entrypoints.openai.api_serverspins up/v1routes.
Verify with:
curl http://localhost:11434/v1/models
You should see your model listed.
4. Point Codex to Your Local Endpoint
Codex uses the OpenAI client libraries. Override the base URL:
Environment variables
export OPENAI_API_BASE=http://localhost:11434/v1
export OPENAI_API_KEY=dummy-key
Node / TypeScript example
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.OPENAI_API_KEY,
baseURL: "http://localhost:11434/v1"
});
The API key can be any string if your local server does not require authentication.
5. Tune Your Model Parameters
- Match the model name exposed by the local backend so the client selects the correct engine and update your client code accordingly.
- Choose
max_tokenshigh enough to cover the longest expected completion but low enough to prevent runaway responses. For large models start around 1024–2048 and adjust after testing; if you need to summarise long RAG documents, push this higher but monitor memory usage. - Adjust
temperaturefor creativity: 0.0–0.3 for deterministic code generation, 0.7–1.0 for brainstorming; tune this if you want more exploratory answers when combined with a local RAG knowledge base. - Ensure the context window matches your coding tasks, if you need multi‑file awareness use a model or build variant that supports extended context (e.g., 8k–32k tokens or more). For local RAG, size the context so retrieved documents fit comfortably.
- Consider tuning
top_pandfrequency_penalty/presence_penaltyto influence diversity and repetition, especially in long conversations. When adding sentiment analysis or RAG, slightly increasingfrequency_penaltycan help avoid repetitive retrieved text. - Review and set
stopsequences to terminate output cleanly when generating structured code or documentation; adapt these when you want the model to stop after a RAG‑provided answer. - For interactive coding agents, set a sensible
streamoption to true so tokens are returned as they are generated, improving perceived responsiveness. If you integrate with OpenWebUI or similar front‑ends, streaming provides real‑time display of both chat and RAG content. - To add local RAG, run a vector database such as Milvus, Weaviate, or use the built‑in retrieval plugin of OpenWebUI. Index your documents and on each user query retrieve relevant chunks, then prepend them to the prompt before sending to the local model.
- With OpenWebUI you can host your model locally and expose a friendly web interface; combine it with your RAG pipeline by configuring a retrieval plugin or custom prompt template so that Codex can answer using both its training data and your private knowledge.
6. Production Tips & Setup Tutorials
Below are step‑by‑step mini‑tutorials for each recommended production technique:
- Run under systemd: create a full service file at
/etc/systemd/system/codex-local.servicesuch as:
[Unit]
Description=Codex Local Llama Server
After=network.target
[Service]
Type=simple
User=codex
Group=codex
WorkingDirectory=/usr/local/share/codex
ExecStart=/usr/local/bin/llama-server --api --host 0.0.0.0 --port 8080 --model /usr/local/share/codex/model.gguf
Restart=always
RestartSec=5s
LimitNOFILE=65535
[Install]
WantedBy=multi-user.target
Then run systemctl daemon-reload && systemctl enable --now codex-local to start on boot and ensure it restarts on failure.
- Run in Docker: write a
Dockerfilethat installs your chosen backend and exposes port 8080. Use the following complete Dockerfile:
FROM debian:stable-slim
RUN apt-get update && apt-get install -y build-essential cmake git && rm -rf /var/lib/apt/lists/*
WORKDIR /app
RUN git clone https://github.com/ggerganov/llama.cpp.git && cd llama.cpp && mkdir build && cd build \
&& cmake -DLLAMA_BLAS=ON .. && make -j$(nproc)
COPY model.gguf /app/llama.cpp/
EXPOSE 8080
CMD ["/app/llama.cpp/build/bin/llama-server","--api","--host","0.0.0.0","--port","8080","--model","/app/llama.cpp/model.gguf"]
Then build and run it:
docker build -t codex-local .
docker run -d -p 8080:8080 codex-local
This provides an isolated container hosting the Codex-compatible API.
- Enable GPU acceleration: For NVIDIA cards install CUDA toolkit and run:
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp && mkdir build && cd build
cmake -DLLAMA_CUBLAS=ON ..
make -j$(nproc)
This compiles with cuBLAS support.
For AMD GPUs install ROCm and use -DLLAMA_HIPBLAS=ON; for Apple Silicon use -DLLAMA_METAL=ON.
If you prefer prebuilt Docker images, add the --gpus all flag when running docker run and ensure the image was built with the correct GPU backend.
Finally verify GPU usage with nvidia-smi or your vendor’s equivalent while generating tokens to confirm that token latency is reduced.
- Build with BLAS for CPU speed: If you do not have a GPU, you can still get good performance by compiling with BLAS (Basic Linear Algebra Subprograms) support.
Step‑by‑step:
- Install a BLAS library (for example on Debian/Ubuntu:
sudo apt install libopenblas-dev, on Arch:sudo pacman -S openblas). - After compilation you will have an optimised
llama-serverbinary that uses OpenBLAS (or the BLAS library you installed) for faster matrix operations.
Run CMake with BLAS enabled:
cmake -DLLAMA_BLAS=ON ..
make -j$(nproc)
Clone the llama.cpp source and create a build directory:
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp && mkdir build && cd build
This is recommended for any CPU‑only server because it can roughly double or triple throughput compared with a plain build, and requires no changes to your model files or API usage.
- Monitor logs: for systemd use
journalctl -u codex-local -for for Dockerdocker logs -f <container>to confirm that Codex requests are reaching your local server.
Bottom Line
OpenAI’s sudden overnight change is frustrating news for developers, many invested weeks of production time only to find that what was once unlimited now demands a costly Pro subscription. This serves as a stark reminder that relying entirely on a third‑party service leaves you vulnerable to abrupt policy shifts. By following the steps above you can:
- keep Codex‑style functionality available even when OpenAI enforces quotas, giving your team freedom and continuity;
- truly own your deployment and data so future policy changes can’t disrupt you;
- develop without interruptions, and with the confidence that your tools will always be there when you need them.
Run Codex locally, and usage limits become a thing of the past.